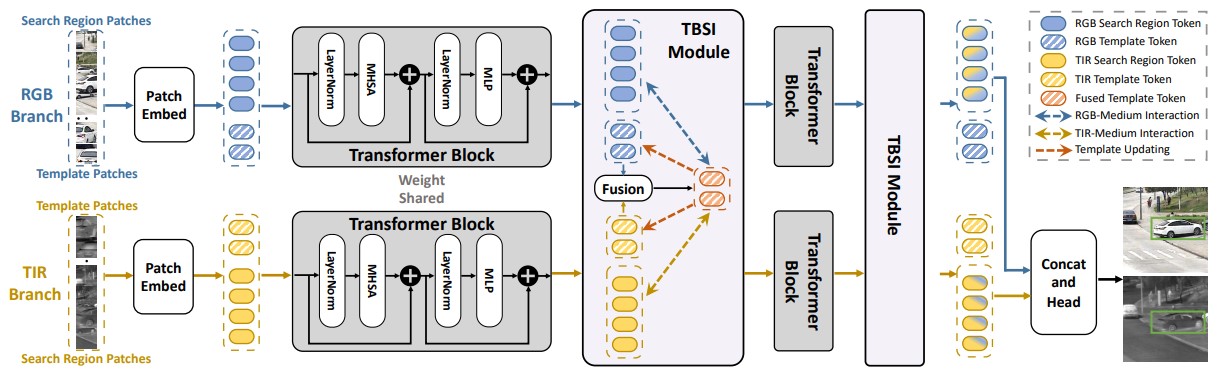
论文来源: Bridging Search Region Interaction With Template for RGB-T Tracking
现有的搜索算法通常会直接连接 RGB 和 T 模态搜索区域, 该方法存在大量冗余背景噪声. 而另一些方法从搜索帧中采样候选框, 对孤立的 RGB 框和 T 框进行各种融合, 这限制了局部区域的跨模态交互. 本文将提出模板桥接搜索区域交互(TBSI)模块, 以模板为媒介, 通过收集和分发目标相关对象和环境来桥接 RGB 和 T 搜索区域之间的跨模态交互.
网络主体结构如上图所示, 其中主干网络为 ViT, 特征经过 Transformer 块的交互与增强后, 进入 TBSI 模块, 该操作重复两次, 最终输出结果被拼接后由预测头进行预测.
输入图像被切割为 P × P P \times P P × P X r o r X t \bm{X}_r \ or \bm{X}_t X r o r X t Z r o r Z t \bm{Z}_r \ or \bm{Z}_t Z r o r Z t
A = S o f t m a x ( Q K ⊤ C ) = S o f t m a x ( [ X q ; Z q ] [ X k ; Z k ] ⊤ C ) = S o f t m a x ( [ X q X k ⊤ , X q Z k ⊤ ; Z q X k ⊤ , Z q Z k ⊤ ] C ) \begin{array}{ll} \bm{A} &= Softmax \left({\large \frac{ \bm{Q} \bm{K}^\top }{ \sqrt{C} } }\right) \\\\ &= Softmax \left({\large \frac{ [\bm{X}_q; \bm{Z}_q][\bm{X}_k; \bm{Z}_k]^\top }{ \sqrt{C} } }\right) \\\\ &= Softmax \left({\large \frac{ [\bm{X}_q \bm{X}_k^\top, \bm{X}_q \bm{Z}_k^\top; \bm{Z}_q \bm{X}_k^\top, \bm{Z}_q \bm{Z}_k^\top] }{ \sqrt{C} } }\right) \end{array} A = S o f t m a x ( C Q K ⊤ ) = S o f t m a x ( C [ X q ; Z q ] [ X k ; Z k ] ⊤ ) = S o f t m a x ( C [ X q X k ⊤ , X q Z k ⊤ ; Z q X k ⊤ , Z q Z k ⊤ ] )
由此我们可以看出, 搜索区域与模板相互聚合彼此的特征, 通过连续 Transformer 块提取搜索区域与模板间的特征. Transformer 块的参数在 RGB 与 T 令牌之间共享, 以避免冗余.
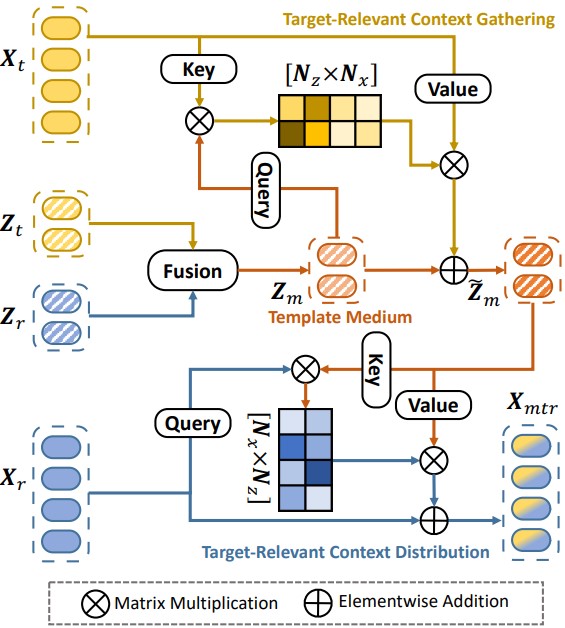
上图展示了 TBSI 模块的详细结构, 图中仅包含 T → M e d i u m → R G B T \rightarrow Medium \rightarrow RGB T → M e d i u m → R G B Z m = [ Z r ; Z t ] W m \bm{Z}_m = [\bm{Z}_r; \bm{Z}_t] \bm{W}_m Z m = [ Z r ; Z t ] W m
D t = S o f t m a x ( ( Z m W q 1 ) ( X t W k 1 ) ⊤ C ) ( X t W v 1 ) \bm{D}_t = Softmax\left( \frac{ (\bm{Z}_m \bm{W}_q^1)(\bm{X}_t \bm{W}_k^1)^\top }{ \sqrt{C} } \right) (\bm{X}_t \bm{W}_v^1) D t = S o f t m a x ( C ( Z m W q 1 ) ( X t W k 1 ) ⊤ ) ( X t W v 1 )
于是我们就能得到细化后的融合特征:
Z m ′ = L N ( Z m + D t ) Z ~ m = L N ( Z m ′ + M L P ( Z m ′ ) ) \bm{Z}'_m = LN(\bm{Z}_m + \bm{D}_t) \\ \tilde{\bm{Z}}_m = LN(\bm{Z}'_m + MLP(\bm{Z}'_m)) Z m ′ = L N ( Z m + D t ) Z ~ m = L N ( Z m ′ + M L P ( Z m ′ ) )
然后计算可见光搜索区域与细化融合特征的交叉注意力:
D m t = S o f t m a x ( ( X r W q 2 ) ( Z ~ m W k 2 ) ⊤ C ) ( Z ~ m W v 2 ) \bm{D}_{mt} = Softmax\left( \frac{ (\bm{X}_r \bm{W}_q^2)(\bm{\tilde{Z}}_m \bm{W}_k^2)^\top }{ \sqrt{C} } \right) (\tilde{\bm{Z}}_m \bm{W}_v^2) D m t = S o f t m a x ( C ( X r W q 2 ) ( Z ~ m W k 2 ) ⊤ ) ( Z ~ m W v 2 )
与细化融合特征的计算方式类似, 下面是细化搜索区域的特征:
X r ′ = L N ( X r + D m t ) X ~ m t r = L N ( X r ′ + M L P ( X r ′ ) ) \bm{X}'_r = LN(\bm{X}_r + \bm{D}_{mt}) \\ \tilde{\bm{X}}_{mtr} = LN(\bm{X}'_r + MLP(\bm{X}'_r)) X r ′ = L N ( X r + D m t ) X ~ m t r = L N ( X r ′ + M L P ( X r ′ ) )
目前为止只经过一次 T r a n s f o r m e r → T B S I Transformer \rightarrow TBSI T r a n s f o r m e r → T B S I
作者与各种在线或离线模型进行对比后, 发现自己设计的网络精度更高, 并且在各种挑战属性上也取得了不错的结果.
base_backbone.py : 该文件是基础骨干网络, 它来自于 OSTrack, 已在本文 中有所解释, 此处不再重复.
模型关键代码位于 vit_tbsi_care.py 中, 其中的 forward_features() 函数覆盖了原本的函数, 我们只需要知道最终输出的 x 是可见光与热模态拼接在一起的数据即可. 重点在于其中的 TBSI 模块, 它位于 tbsi_layer.py 中. 下面给出了 forward_features() 函数的详细注释.
展开以查看详细注释 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def forward_features (self, z, x ): B, H, W = x[0 ].shape[0 ], x[0 ].shape[2 ], x[0 ].shape[3 ] x_v = self.patch_embed(x[0 ]) z_v = self.patch_embed(z[0 ]) x_i = self.patch_embed(x[1 ]) z_i = self.patch_embed(z[1 ]) if self.add_cls_token: cls_tokens = self.cls_token.expand(B, -1 , -1 ) cls_tokens = cls_tokens + self.cls_pos_embed z_v += self.pos_embed_z x_v += self.pos_embed_x z_i += self.pos_embed_z x_i += self.pos_embed_x if self.add_sep_seg: x += self.search_segment_pos_embed z += self.template_segment_pos_embed x_v = combine_tokens(z_v, x_v, mode=self.cat_mode) x_i = combine_tokens(z_i, x_i, mode=self.cat_mode) if self.add_cls_token: x = torch.cat([cls_tokens, x], dim=1 ) x_v = self.pos_drop(x_v) x_i = self.pos_drop(x_i) lens_z = self.pos_embed_z.shape[1 ] lens_x = self.pos_embed_x.shape[1 ] tbsi_index = 0 for i, blk in enumerate (self.blocks): x_v = blk(x_v) x_i = blk(x_i) if self.tbsi_loc is not None and i in self.tbsi_loc: x_v, x_i = self.tbsi_layers[tbsi_index](x_v, x_i, lens_z) tbsi_index += 1 x_v = recover_tokens(x_v, lens_z, lens_x, mode=self.cat_mode) x_i = recover_tokens(x_i, lens_z, lens_x, mode=self.cat_mode) x = torch.cat([x_v, x_i], dim=1 ) aux_dict = {"attn" : None } return self.norm(x), aux_dict
现在来查看 TBSI 模块. 再回顾一下前面的模块示意图.
现在来解析代码, 直接看 forward() 函数, 首先作者使用融合模块将两个模板区域融合, 得到 Z m \bm{Z}_m Z m CASTBlock, 该模块位于 attn_block.py 中, 其中 forward() 函数代码仅两行, 对应了 Z m → Z ~ m \bm{Z}_m \rightarrow \tilde{\bm{Z}}_m Z m → Z ~ m Attention_st 中, 在文件 attn.py 里.
接下来我们逐行解析.
1 fused_t = self.ca_s2t_i2f(torch.cat([fused_t, x_i[:, lens_z:, :]], dim=1 ))[:, :lens_z, :]
输入是 [ Z m , X t ] [\bm{Z}_m, \bm{X}_t] [ Z m , X t ] s2t, 该模式下 Q \bm{Q} Q Z m \bm{Z}_m Z m K , V \bm{K}, \bm{V} K , V X t \bm{X}_t X t [ Z ~ m , K ] [\tilde{\bm{Z}}_m, \bm{K}] [ Z ~ m , K ] Z ~ m \tilde{\bm{Z}}_m Z ~ m fused_t.
1 temp_x_v = self.ca_t2s_f2v(torch.cat([fused_t, x_v[:, lens_z:, :]], dim=1 ))[:, lens_z:, :]
输入是 [ Z ~ m , X r ] [\tilde{\bm{Z}}_m, \bm{X}_r] [ Z ~ m , X r ] t2s, 该模型下 Q \bm{Q} Q X r \bm{X}_r X r K , V \bm{K}, \bm{V} K , V Z ~ m \tilde{\bm{Z}}_m Z ~ m [ K , X m t r ] [\bm{K}, \bm{X}_{mtr}] [ K , X m t r ] X m t r \bm{X}_{mtr} X m t r temp_x_v.
1 2 fused_t = self.ca_s2t_v2f(torch.cat([fused_t, x_v[:, lens_z:, :]], dim=1 ))[:, :lens_z, :] temp_x_i = self.ca_t2s_f2i(torch.cat([fused_t, x_i[:, lens_z:, :]], dim=1 ))[:, lens_z:, :]
重复上述过程, 但之前是用热红外补充可见光, 现在是可见光补充热红外.
1 2 x_v[:, lens_z:, :] = temp_x_v x_i[:, lens_z:, :] = temp_x_i
将上面经过补充的搜索区域特征替换掉原始的特征.
1 x_v[:, :lens_z, :] = self.ca_t2t_f2v(torch.cat([x_v[:, :lens_z, :], fused_t], dim=1 ))[:, :lens_z, :]
输入是 [ Z r , Z ~ m ] [\bm{Z}_r, \tilde{\bm{Z}}_m] [ Z r , Z ~ m ] t2t, 该模式下 Q \bm{Q} Q Z r \bm{Z}_r Z r K , V \bm{K}, \bm{V} K , V Z ~ m \tilde{\bm{Z}}_m Z ~ m
1 x_i[:, :lens_z, :] = self.ca_t2t_f2i(torch.cat([x_i[:, :lens_z, :], fused_t], dim=1 ))[:, :lens_z, :]
与上文同理.
最后返回使用另一模态补充的模板和搜索区域.
TBSI 模块将与 Transformer 交替进行. 最终使用预测头进行预测.