简介
论文来源: Unified Single-Stage Transformer Network for Efficient RGB-T Tracking
现有的网络通常以单独的方式提取模态特征, 缺乏模态之间的交互与指导, 三阶段融合策略极大地限制了跟踪速度. 本文作者将提出一个统一的单级 Transformer RGB-T 追踪方法, 即 USTrack, 它将三阶段统一为一个 ViT 主干, 通过双层嵌入自注意力机制, 让模型能够在模态相互交互的前提下进行特征融合. 此外, 作者还引入了一种新颖的特征选择机制, 以减轻无效模态对预测的影响.
方法
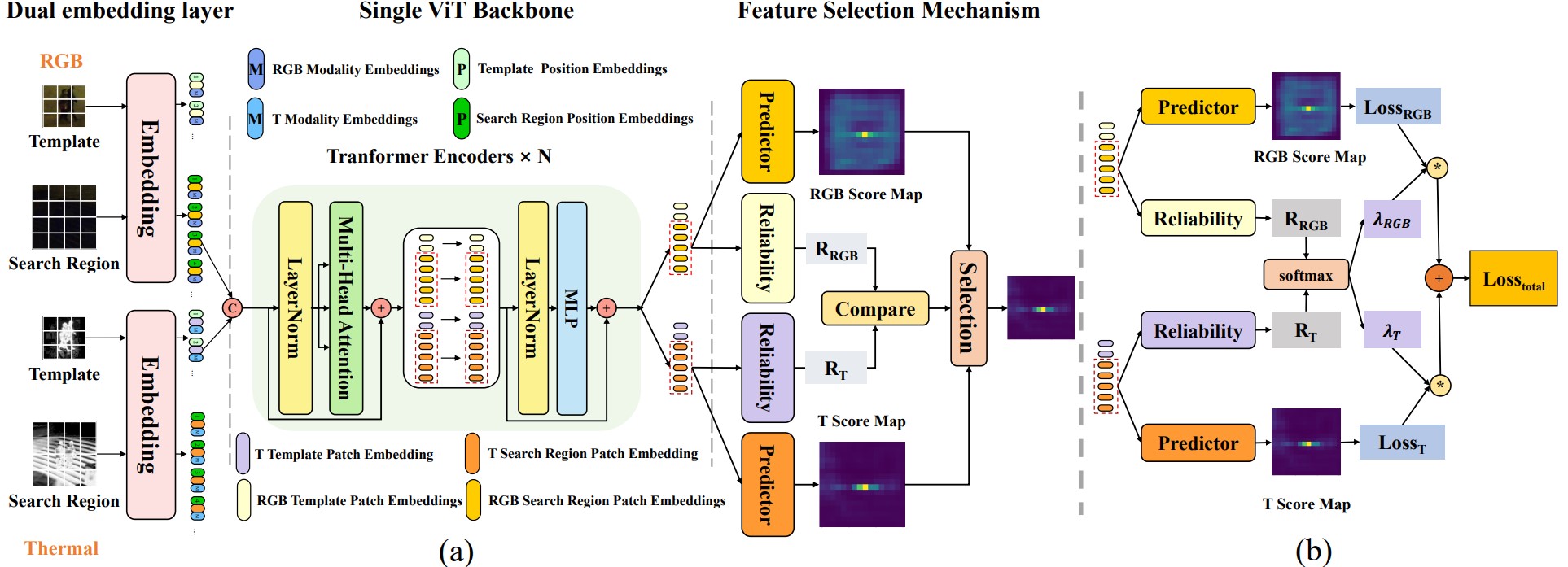
网络的输入包括 4 张图: RGB 模板 zimagergb∈RHz×Wz×3, RGB 搜索区域 ximagergb∈RHx×Wx×3, 热红外模板 zimaget∈RHz×Wz×3, 热红外搜索区域 ximaget∈RHx×Wx×3.
与 ViT 一致, 它们将被切割为 patch, 并使用投影矩阵 Ergb,Et 来映射到 D 维潜在空间中. 不同点在于, ViT 只添加了位置嵌入 P, 而本文还添加了模态嵌入 M:
z~rgbz~tx~rgbx~t=[zrgb1Ergb;zrgb2Ergb;⋯;zrgbNzErgb]+Pz+Mrgb=[zt1Et;zt2Et;⋯;ztNzEt]+Pz+Mt=[xrgb1Ergb;xrgb2Ergb;⋯;xrgbNxErgb]+Px+Mrgb=[xt1Et;xt2Et;⋯;xtNxEt]+Px+Mt
这些序列将被拼接为新的标记序列 H=[x~rgb;x~t;z~rgb;z~t]∈R(2Nx+2Nt)×D, 对其使用多头注意力:
M=A⋅V=Softmax(dkQK⊤)⋅VQK⊤=[Qrgbx;Qtx;Qrgbz;Qtz][Krgbx;Ktx;Krgbz;Ktz]⊤V=[Vrgbx;Vtx;Vrgbz;Vtz]
将 QK⊤ 展开得到:
==QK⊤[QrgbxKrgbx⊤,QrgbxKtx⊤,QrgbxKrgbz⊤,QrgbxKtz⊤;⋯][Wxrgbxrgb,Wxtxrgb,Wzrgbxrgb,Wztxrgb;⋯]
最终的注意力表达式可以写作:
M=[WxrgbxrgbVrgbx+WxtxrgbVtx+WzrgbxrgbVtz+WztxrgbVtz;⋯]
其中 WxrgbxrgbVrgbx 表示 RGB 搜索区域图像特征提取, WxtxrgbVtx 根据两个模态之间的语义相似性来聚合热模态特定信息, WzrgbxrgbVtz 负责聚合 RGB 模板图像特征, 以获取搜索区域与模板间的关系信息, WztxrgbVtz 负责聚合热红外模板图像特征, 获取热红外模板与 RGB 搜索区域之间的关系.
仅通过自注意力的全局感知能力, 作者就已将特征提取, 特征融合与关系建模统一到单个 ViT 主干中, 使得该网络能够在模态交互的作用下直接提取模板和搜索区域的融合特征.
ViT 骨干的输出是两个融合特征, 它们分别以 RGB 和热红外作为主导, 并辅以另一模态的信息. 由于两个融合特征都包括了模态融合信息, 以及模板与搜索区域的关系信息, 因此两者都可以直接用于目标位置预测. 上图 (b) 展示了训练过程中的损失函数计算方式, 两个融合特征具有相同的损失函数, 可靠性评估模块输出可靠性权重, 用以组合成最终损失函数. 该方案允许不可靠模态产生较差的结果, 然后由可靠性评估模块给出较低权重, 而更可靠的模态将得到更大的权重.
作者采用 OSTrack 的预测头作为本文预测头, 两个预测头对应的损失函数如下:
LRGB=LclsRGB+λgiouLgiouRGB+λL1L1RGBLT=LclsT+λgiouLgiouT+λL1L1T
其中 LRGB,LT 是每个预测头的整体损失函数, LclsRGB,LclsT 是 focal loss, LgiouRGB,LgiouT 是广义 IoU 损失. 评估模块由多个 Conv−BN−ReLU 组成, 为了防止权重被归零, 使用 Softmax 处理后的结果作为新的权重:
λRGB,λT=Softmax(RRGB,RT)Ltotal=λRGBLRGB+λTLT