论文来源: Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
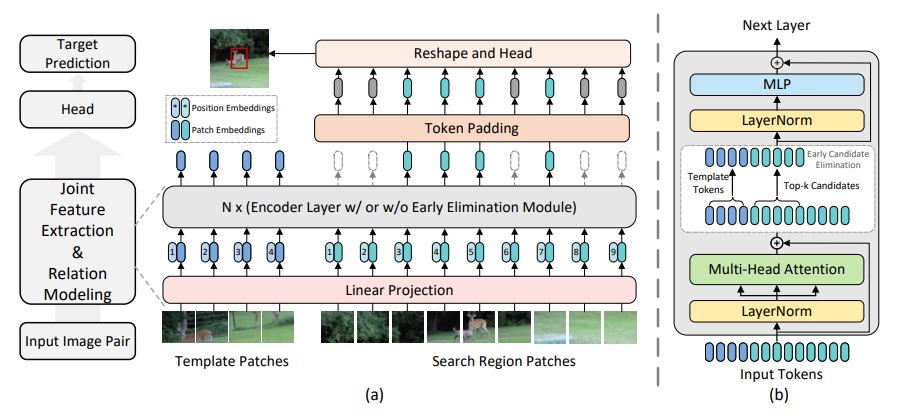
当前流行的各种模型都是将模板提取与区域搜索分成两个分支, 再进行关系建模, 因而在提取特征阶段难以感知目标与背景区别. 为了解决该问题, 作者提出了一种单流跟踪框架, 以统一特征学习与关系建模. 由于该框架是高度并行的, 因此计算效率极高.
对于模板 z ∈ R 3 × H z × W z z \in \mathbb{R}^{3 \times H_z \times W_z} z ∈ R 3 × H z × W z x ∈ R 3 × H x × W x x \in \mathbb{R}^{3 \times H_x \times W_x} x ∈ R 3 × H x × W x z p ∈ R N z × ( 3 ⋅ P 2 ) , x p ∈ R N x × ( 3 ⋅ P 2 ) z_p \in \mathbb{R}^{N_z \times (3 \cdot P^2)}, x_p \in \mathbb{R}^{N_x \times (3 \cdot P^2)} z p ∈ R N z × ( 3 ⋅ P 2 ) , x p ∈ R N x × ( 3 ⋅ P 2 ) P × P P \times P P × P N z = H z W z / P 2 , N x = H x W x / P 2 N_z = H_z W_z / P^2, N_x = H_x W_x / P^2 N z = H z W z / P 2 , N x = H x W x / P 2 E \bm E E D D D
H z 0 = [ z p 1 E ; z p 2 E ; ⋯ ; z p N z E ] + P z , E ∈ R ( 3 ⋅ P 2 ) × D , P z ∈ R N z × D H x 0 = [ x p 1 E ; x p 2 E ; ⋯ ; x p N x E ] + P x , P x ∈ R N x × D \begin{array}{ll} \bm{H}_z^0 = [z_p^1 \bm{E}; z_p^2 \bm{E}; \cdots; z_p^{N_z} \bm{E}] + \bm{P}_z, \bm{E} \in \mathbb{R}^{(3 \cdot P^2) \times D}, \bm{P}_z \in \mathbb{R}^{N_z \times D} \\ \bm{H}_x^0 = [x_p^1 \bm{E}; x_p^2 \bm{E}; \cdots; x_p^{N_x} \bm{E}] + \bm{P}_x, \bm{P}_x \in \mathbb{R}^{N_x \times D} \end{array} H z 0 = [ z p 1 E ; z p 2 E ; ⋯ ; z p N z E ] + P z , E ∈ R ( 3 ⋅ P 2 ) × D , P z ∈ R N z × D H x 0 = [ x p 1 E ; x p 2 E ; ⋯ ; x p N x E ] + P x , P x ∈ R N x × D
该投影的输出称为 patch 嵌入, P x , P z \bm{P}_x, \bm{P}_z P x , P z
将两个令牌序列连接, 得到 E z x 0 = [ E z 0 ; E x 0 ] \bm{E}_{zx}^0 = [\bm{E}_z^0; \bm{E}_x^0] E z x 0 = [ E z 0 ; E x 0 ]
A = S o f t m a x ( Q K ⊤ d k ) ⋅ V = S o f t m a x ( [ Q z ; Q x ] [ K z ; K x ] ⊤ d k ) ⋅ [ V z ; V x ] A = Softmax(\frac{\bm{Q}\bm{K}^\top}{\sqrt{d_k}}) \cdot \bm{V} = Softmax(\frac{[\bm{Q}_z;\bm{Q}_x] [\bm{K}_z;\bm{K}_x]^\top}{\sqrt{d_k}}) \cdot [\bm{V}_z;\bm{V}_x] A = S o f t m a x ( d k Q K ⊤ ) ⋅ V = S o f t m a x ( d k [ Q z ; Q x ] [ K z ; K x ] ⊤ ) ⋅ [ V z ; V x ]
下标 z , x z, x z , x
S o f t m a x ( [ Q z ; Q x ] [ K z ; K x ] ⊤ d k ) = S o f t m a x ( [ Q z K z ⊤ , Q z K x ⊤ ; Q x K z ⊤ , Q x K x ⊤ ] d k ) ≜ [ W z z , W z x ; W x z , W x x ] \large \begin{array}{ll} & Softmax(\frac{[\bm{Q}_z;\bm{Q}_x] [\bm{K}_z;\bm{K}_x]^\top}{\sqrt{d_k}}) \\ =& Softmax(\frac{[\bm{Q}_z\bm{K}_z^\top, \bm{Q}_z\bm{K}_x^\top; \bm{Q}_x\bm{K}_z^\top, \bm{Q}_x\bm{K}_x^\top]}{\sqrt{d_k}}) \\ \triangleq & [\bm{W}_{zz}, \bm{W}_{zx}; \bm{W}_{xz}, \bm{W}_{xx}] \end{array} = ≜ S o f t m a x ( d k [ Q z ; Q x ] [ K z ; K x ] ⊤ ) S o f t m a x ( d k [ Q z K z ⊤ , Q z K x ⊤ ; Q x K z ⊤ , Q x K x ⊤ ] ) [ W z z , W z x ; W x z , W x x ]
乘上 V V V
A = [ W z z V z + W z x V x ; W x z V z + W x x V x ] A = [\bm{W}_{zz} \bm{V}_z + \bm{W}_{zx} \bm{V}_x; \bm{W}_{xz} \bm{V}_z + \bm{W}_{xx} \bm{V}_x] A = [ W z z V z + W z x V x ; W x z V z + W x x V x ]
W x z V z \bm{W}_{xz} \bm{V}_z W x z V z W x x V x \bm{W}_{xx} \bm{V}_x W x x V x
为了降低运算量, 作者设计了候选淘汰机制, 它被集成在编码器中. 我们给每个模板 patch 设置一个标记 h z i , 1 ≤ i ≤ N z \bm{h}_z^i, 1 \leq i \leq N_z h z i , 1 ≤ i ≤ N z
h z i = S o f t m a x ( q i ⋅ [ K z ; K x ] ⊤ d ) ⋅ V = [ w z i ; w x i ] ⋅ V \bm{h}_z^i = Softmax(\frac{\bm{q}_i \cdot [\bm{K}_z; \bm{K}_x]^\top}{\sqrt{d}}) \cdot \bm{V} = [\bm{w}_z^i; \bm{w}_x^i] \cdot \bm{V} h z i = S o f t m a x ( d q i ⋅ [ K z ; K x ] ⊤ ) ⋅ V = [ w z i ; w x i ] ⋅ V
其中 q i \bm{q}_i q i h z i \bm{h}_z^i h z i w x i \bm{w}_x^i w x i h z i \bm{h}_z^i h z i
w x ϕ , ϕ = ⌊ W z 2 ⌋ + W z ⋅ ⌊ H z 2 ⌋ \bm{w}_x^{\phi}, \phi = \left\lfloor \frac{W_z}{2} \right\rfloor + W_z \cdot \left\lfloor \frac{H_z}{2} \right\rfloor w x ϕ , ϕ = ⌊ 2 W z ⌋ + W z ⋅ ⌊ 2 H z ⌋
考虑到 ViT 中使用了多头自注意力, 因而我们将得到多个相似度分数, 使用平均数来表示最终相似度:
w ˉ x ϕ = 1 M ∑ m = 1 M w x ϕ ( m ) \bar{w}_x^\phi = \frac1M \sum\limits_{m=1}^{M} w_x^\phi(m) w ˉ x ϕ = M 1 m = 1 ∑ M w x ϕ ( m )
我们一般认为模板与候选区域相似度越大, 该候选区域就是待追踪目标的可能性越大, 因而我们只需要保留前 k k k
最后, 将搜索区域序列转换为二维特征图, 使用全卷积网络 ( L (L ( L C o n v − B N − R e L U Conv-BN-ReLU C o n v − B N − R e L U ) ) ) P ∈ [ 0 , 1 ] H x P × W x P \bm{P} \in [0, 1]^{\frac{H_x}P \times \frac{W_x}P} P ∈ [ 0 , 1 ] P H x × P W x O ∈ [ 0 , 1 ) 2 × H x P × W x P \bm{O} \in [0, 1)^{2 \times \frac{H_x}P \times \frac{W_x}P} O ∈ [ 0 , 1 ) 2 × P H x × P W x S ∈ [ 0 , 1 ] 2 × H x P × W x P \bm{S} \in [0, 1]^{2 \times \frac{H_x}P \times \frac{W_x}P} S ∈ [ 0 , 1 ] 2 × P H x × P W x ( x d , y d ) = arg max ( x , y ) P x y (x_d, y_d) = \argmax _{(x, y)}\bm{P}_{xy} ( x d , y d ) = a r g m a x ( x , y ) P x y
{ x = x d + O ( 0 , x d , y d ) y = y d + O ( 1 , x d , y d ) w = S ( 0 , x d , y d ) h = S ( 1 , x d , y d ) \left \{ \begin{array}{ll} x = x_d + \bm{O}(0, x_d, y_d) \\ y = y_d + \bm{O}(1, x_d, y_d) \\ w = \bm{S}(0, x_d, y_d) \\ h = \bm{S}(1, x_d, y_d) \end{array} \right. ⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ x = x d + O ( 0 , x d , y d ) y = y d + O ( 1 , x d , y d ) w = S ( 0 , x d , y d ) h = S ( 1 , x d , y d )
对于损失函数, 同时使用分类损失与回归损失, 使用加权焦点损失进行分类, 通过预测边界框, 使用 l 1 l1 l 1 I o U IoU I o U
L t r a c k = L c l s + λ i o u L i o u + λ L 1 L 1 L_{track} = L_{cls} + \lambda_{iou} L_{iou} + \lambda_{L_1}L_1 L t r a c k = L c l s + λ i o u L i o u + λ L 1 L 1
源码地址: https://github.com/botaoye/OSTrack , 模型代码在 ./lib/models 文件夹中.
按照正常人的思路, ostrack.py 就是模型文件, 现在我们查看该文件, 不难发现, 其中最重要的就是 self.backbone 和 self.forward_head.
先看 backbone, 通过检查调用可以发现其实际上是 VisionTransformerCE, 集成关系为: VisionTransformerCE-VisionTransformer-BaseBackbone.
首先查看 base_backbone.py 文件, 里面定义了基础骨干网络, 在构造函数中定义了图像尺寸, 嵌入层等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def __init__ (self ): super ().__init__() self.pos_embed = None self.img_size = [224 , 224 ] self.patch_size = 16 self.embed_dim = 384 self.cat_mode = 'direct' self.pos_embed_z = None self.pos_embed_x = None self.template_segment_pos_embed = None self.search_segment_pos_embed = None self.return_inter = False self.return_stage = [2 , 5 , 8 , 11 ] self.add_cls_token = False self.add_sep_seg = False
前向过程中调用了 forward_features() 函数, 其输入是模板与搜索区域, 查看该函数源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 def forward_features (self, z, x ): B, H, W = x.shape[0 ], x.shape[2 ], x.shape[3 ] x = self.patch_embed(x) z = self.patch_embed(z) if self.add_cls_token: cls_tokens = self.cls_token.expand(B, -1 , -1 ) cls_tokens = cls_tokens + self.cls_pos_embed z += self.pos_embed_z x += self.pos_embed_x if self.add_sep_seg: x += self.search_segment_pos_embed z += self.template_segment_pos_embed x = combine_tokens(z, x, mode=self.cat_mode) if self.add_cls_token: x = torch.cat([cls_tokens, x], dim=1 ) x = self.pos_drop(x) for i, blk in enumerate (self.blocks): x = blk(x) lens_z = self.pos_embed_z.shape[1 ] lens_x = self.pos_embed_x.shape[1 ] x = recover_tokens(x, lens_z, lens_x, mode=self.cat_mode) aux_dict = {"attn" : None } return self.norm(x), aux_dict
注意到里面将 x , z x, z x , z patch_embed.py 中.
1 2 3 4 5 6 7 8 9 10 11 12 def forward (self, x ): x = self.proj(x) if self.flatten: x = x.flatten(2 ).transpose(1 , 2 ) x = self.norm(x) return x
可以看出最终输出的维数是 x ∈ R B × N x × D x \in \mathbb{R}^{B \times N_x \times D} x ∈ R B × N x × D
此时还剩下 finetune_track() 这个函数没用到, 实际上该函数是在 ostrack.py 的 build_ostrack() 函数中调用的, 用于对模型进行微调.
在这之前需要先查看 vit_ce.py 的部分代码, 这是 ViT 的实现代码, 后面的 ce 表示候选消除. 其中的 VisionTransformer 类继承了上面的主干网络, 其构造函数中定义的一些参数将会在之后用到. 我们只需要关注以下几个参数.
1 2 3 4 5 6 7 self.cls_token = nn.Parameter(torch.zeros(1 , 1 , embed_dim)) self.dist_token = nn.Parameter(torch.zeros(1 , 1 , embed_dim)) if distilled else None self.pos_embed = nn.Parameter(torch.zeros(1 , num_patches + self.num_tokens, embed_dim)) self.pos_drop = nn.Dropout(p=drop_rate)
位置编码的维数是 num_patches + self.num_tokens, 其中 self.num_tokens = 2 if distilled else 1 用于留出位置给分类器. 而 self.pos_embed 则可以猜测出其维数含义是: 批大小(使用广播机制自动扩展)-patch数量-特征维数.
再回到 finetune_track() 函数, 现在我们就能更方便的理解各行代码含义. 其中有一行代码是 patch_pos_embed = self.pos_embed[:, patch_start_index:, :], 其中 patch 起始位置一般为 1, 这是因为 self.pos_embed 的第一个是分类器标记, 需要排除.
该函数后半部分的代码用于向 patch 中添加位置编码, 它将原位置编码插值为新的维数, 以应用到模板与搜索区域上来.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 def finetune_track (self, cfg, patch_start_index=1 ): search_size = to_2tuple(cfg.DATA.SEARCH.SIZE) template_size = to_2tuple(cfg.DATA.TEMPLATE.SIZE) new_patch_size = cfg.MODEL.BACKBONE.STRIDE self.cat_mode = cfg.MODEL.BACKBONE.CAT_MODE self.return_inter = cfg.MODEL.RETURN_INTER self.return_stage = cfg.MODEL.RETURN_STAGES self.add_sep_seg = cfg.MODEL.BACKBONE.SEP_SEG if new_patch_size != self.patch_size: print ('Inconsistent Patch Size With The Pretrained Weights, Interpolate The Weight!' ) old_patch_embed = {} for name, param in self.patch_embed.named_parameters(): if 'weight' in name: param = nn.functional.interpolate(param, size=(new_patch_size, new_patch_size), mode='bicubic' , align_corners=False ) param = nn.Parameter(param) old_patch_embed[name] = param self.patch_embed = PatchEmbed(img_size=self.img_size, patch_size=new_patch_size, in_chans=3 , embed_dim=self.embed_dim) self.patch_embed.proj.bias = old_patch_embed['proj.bias' ] self.patch_embed.proj.weight = old_patch_embed['proj.weight' ] patch_pos_embed = self.pos_embed[:, patch_start_index:, :] patch_pos_embed = patch_pos_embed.transpose(1 , 2 ) B, E, Q = patch_pos_embed.shape P_H, P_W = self.img_size[0 ] // self.patch_size, self.img_size[1 ] // self.patch_size patch_pos_embed = patch_pos_embed.view(B, E, P_H, P_W) H, W = search_size new_P_H, new_P_W = H // new_patch_size, W // new_patch_size search_patch_pos_embed = nn.functional.interpolate(patch_pos_embed, size=(new_P_H, new_P_W), mode='bicubic' , align_corners=False ) search_patch_pos_embed = search_patch_pos_embed.flatten(2 ).transpose(1 , 2 ) H, W = template_size new_P_H, new_P_W = H // new_patch_size, W // new_patch_size template_patch_pos_embed = nn.functional.interpolate(patch_pos_embed, size=(new_P_H, new_P_W), mode='bicubic' , align_corners=False ) template_patch_pos_embed = template_patch_pos_embed.flatten(2 ).transpose(1 , 2 ) self.pos_embed_z = nn.Parameter(template_patch_pos_embed) self.pos_embed_x = nn.Parameter(search_patch_pos_embed) if self.add_cls_token and patch_start_index > 0 : cls_pos_embed = self.pos_embed[:, 0 :1 , :] self.cls_pos_embed = nn.Parameter(cls_pos_embed) if self.add_sep_seg: self.template_segment_pos_embed = nn.Parameter(torch.zeros(1 , 1 , self.embed_dim)) self.template_segment_pos_embed = trunc_normal_(self.template_segment_pos_embed, std=.02 ) self.search_segment_pos_embed = nn.Parameter(torch.zeros(1 , 1 , self.embed_dim)) self.search_segment_pos_embed = trunc_normal_(self.search_segment_pos_embed, std=.02 ) if self.return_inter: for i_layer in self.return_stage: if i_layer != 11 : norm_layer = partial(nn.LayerNorm, eps=1e-6 ) layer = norm_layer(self.embed_dim) layer_name = f'norm{i_layer} ' self.add_module(layer_name, layer)
了解完基础骨干, 就可以开始看 VisionTransformerCE, 在构造函数中有一个循环, 它首先判断第 i i i i ∈ c e _ l o c i \in ce\_loc i ∈ c e _ l o c ce_loc 是一个数组, 用于判断哪基层需要消除, 一般为 [3, 6, 9], 在各个模型的 YAML 配置文件中可以修改, ce_keep_ratio_i 默认为 1.0, 它表示持有比, 也就是最终保留多少 patch, 默认配置为 0.7, 即移除 30 % 30\% 3 0 % 1.0. 最后, 向 blocks 中添加 CEBlock.
CEBlock 包含了候选消除的功能, 我们先暂时跳过该部分, 阅读 VisionTransformerCE 的 forward_features() 函数, 此部分的重点是对消除后的 tokens 序列进行处理, 让被移除的区域填充零, 并保持原始顺序不变.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 def forward_features (self, z, x, mask_z=None , mask_x=None , ce_template_mask=None , ce_keep_rate=None , return_last_attn=False ): B, H, W = x.shape[0 ], x.shape[2 ], x.shape[3 ] x = self.patch_embed(x) z = self.patch_embed(z) if mask_z is not None and mask_x is not None : mask_z = F.interpolate(mask_z[None ].float (), scale_factor=1. / self.patch_size).to(torch.bool )[0 ] mask_z = mask_z.flatten(1 ).unsqueeze(-1 ) mask_x = F.interpolate(mask_x[None ].float (), scale_factor=1. / self.patch_size).to(torch.bool )[0 ] mask_x = mask_x.flatten(1 ).unsqueeze(-1 ) mask_x = combine_tokens(mask_z, mask_x, mode=self.cat_mode) mask_x = mask_x.squeeze(-1 ) if self.add_cls_token: cls_tokens = self.cls_token.expand(B, -1 , -1 ) cls_tokens = cls_tokens + self.cls_pos_embed z += self.pos_embed_z x += self.pos_embed_x if self.add_sep_seg: x += self.search_segment_pos_embed z += self.template_segment_pos_embed x = combine_tokens(z, x, mode=self.cat_mode) if self.add_cls_token: x = torch.cat([cls_tokens, x], dim=1 ) x = self.pos_drop(x) lens_z = self.pos_embed_z.shape[1 ] lens_x = self.pos_embed_x.shape[1 ] global_index_t = torch.linspace(0 , lens_z - 1 , lens_z).to(x.device) global_index_t = global_index_t.repeat(B, 1 ) global_index_s = torch.linspace(0 , lens_x - 1 , lens_x).to(x.device) global_index_s = global_index_s.repeat(B, 1 ) removed_indexes_s = [] for i, blk in enumerate (self.blocks): x, global_index_t, global_index_s, removed_index_s, attn = \ blk(x, global_index_t, global_index_s, mask_x, ce_template_mask, ce_keep_rate) if self.ce_loc is not None and i in self.ce_loc: removed_indexes_s.append(removed_index_s) x = self.norm(x) lens_x_new = global_index_s.shape[1 ] lens_z_new = global_index_t.shape[1 ] z = x[:, :lens_z_new] x = x[:, lens_z_new:] if removed_indexes_s and removed_indexes_s[0 ] is not None : removed_indexes_cat = torch.cat(removed_indexes_s, dim=1 ) pruned_lens_x = lens_x - lens_x_new pad_x = torch.zeros([B, pruned_lens_x, x.shape[2 ]], device=x.device) x = torch.cat([x, pad_x], dim=1 ) index_all = torch.cat([global_index_s, removed_indexes_cat], dim=1 ) C = x.shape[-1 ] x = torch.zeros_like(x).scatter_(dim=1 , index=index_all.unsqueeze(-1 ).expand(B, -1 , C).to(torch.int64), src=x) x = recover_tokens(x, lens_z_new, lens_x, mode=self.cat_mode) x = torch.cat([z, x], dim=1 ) aux_dict = { "attn" : attn, "removed_indexes_s" : removed_indexes_s, } return x, aux_dict
最后来看实现候选消除的 CEBlock, 我们直接看 forward() 函数. 除了注意力以外, 后面使用了 candidate_elimination() 函数进行消除操作. 其中 attn 来自 attn.py 中的 attn = (q @ k.transpose(-2, -1)) * self.scale 一行, 其中 q , k ∈ R N × C \bm{q}, \bm{k} \in \mathbb{R}^{N \times C} q , k ∈ R N × C a t t n ∈ R N × N attn \in \mathbb{R}^{N \times N} a t t n ∈ R N × N t t t s s s a t t n attn a t t n
a t t n = ( t 1 t 1 ⋯ t 1 t l e n s _ t t 1 s 1 ⋯ t 1 s l e n s _ s ⋮ ⋱ ⋮ ⋮ ⋱ ⋮ t l e n s _ t t l e n s _ t ⋯ t l e n s _ t t l e n s _ t t l e n s _ t s 1 ⋯ t l e n s _ t s l e n s _ s s 1 t 1 ⋯ s 1 t l e n s _ t s 1 s 1 ⋯ s 1 s l e n s _ s ⋮ ⋱ ⋮ ⋮ ⋱ ⋮ s l e n s _ s t 1 ⋯ s l e n s _ s t l e n s _ t s l e n s _ s s 1 ⋯ s l e n s _ s s l e n s _ s ) attn = \begin{pmatrix} t_1 t_1 & \cdots & t_1 t_{lens\_t} & \color{red}t_1 s_1 & \color{red} \cdots & \color{red} t_1 s_{lens\_s} \\ \vdots & \ddots & \vdots & \color{red} \vdots & \color{red} \ddots & \color{red} \vdots \\ t_{lens\_t} t_{lens\_t} & \cdots & t_{lens\_t} t_{lens\_t} & \color{red} t_{lens\_t} s_1 & \color{red} \cdots & \color{red} t_{lens\_t} s_{lens\_s} \\ s_1 t_1 & \cdots & s_1 t_{lens\_t} & s_1 s_1 & \cdots & s_1 s_{lens\_s} \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ s_{lens\_s} t_1 & \cdots & s_{lens\_s} t_{lens\_t} & s_{lens\_s} s_1 & \cdots & s_{lens\_s} s_{lens\_s} \end{pmatrix} a t t n = ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ t 1 t 1 ⋮ t l e n s _ t t l e n s _ t s 1 t 1 ⋮ s l e n s _ s t 1 ⋯ ⋱ ⋯ ⋯ ⋱ ⋯ t 1 t l e n s _ t ⋮ t l e n s _ t t l e n s _ t s 1 t l e n s _ t ⋮ s l e n s _ s t l e n s _ t t 1 s 1 ⋮ t l e n s _ t s 1 s 1 s 1 ⋮ s l e n s _ s s 1 ⋯ ⋱ ⋯ ⋯ ⋱ ⋯ t 1 s l e n s _ s ⋮ t l e n s _ t s l e n s _ s s 1 s l e n s _ s ⋮ s l e n s _ s s l e n s _ s ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞
我们只需要右上角 l e n s _ t × l e n s _ s lens\_ t \times lens\_ s l e n s _ t × l e n s _ s candidate_elimination() 中, 作者使用了 attn_t = attn[:, :, :lens_t, lens_t:], 该代码的含义是取出前 l e n s _ t lens\_t l e n s _ t l e n s _ t lens\_t l e n s _ t 0 0 0
接下来就是 box_mask_z, 它来自 ./lib/utils/ce_utils.py 中的 generate_mask_cond() 函数, 观察代码可以看出它实际上是一个仅中间值取 True, 其他全为 False 的数组, 其作用是取出中间位置的值, 再求多头注意力平均数, 随后使用 sort 降序排列, 取出前 l e n s _ k e e p lens\_keep l e n s _ k e e p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 def candidate_elimination (attn: torch.Tensor, tokens: torch.Tensor, lens_t: int , keep_ratio: float , global_index: torch.Tensor, box_mask_z: torch.Tensor ): """ Eliminate potential background candidates for computation reduction and noise cancellation. Args: attn (torch.Tensor): [B, num_heads, L_t + L_s, L_t + L_s], attention weights tokens (torch.Tensor): [B, L_t + L_s, C], template and search region tokens lens_t (int): length of template keep_ratio (float): keep ratio of search region tokens (candidates) global_index (torch.Tensor): global index of search region tokens box_mask_z (torch.Tensor): template mask used to accumulate attention weights Returns: tokens_new (torch.Tensor): tokens after candidate elimination keep_index (torch.Tensor): indices of kept search region tokens removed_index (torch.Tensor): indices of removed search region tokens """ lens_s = attn.shape[-1 ] - lens_t bs, hn, _, _ = attn.shape lens_keep = math.ceil(keep_ratio * lens_s) if lens_keep == lens_s: return tokens, global_index, None attn_t = attn[:, :, :lens_t, lens_t:] if box_mask_z is not None : box_mask_z = box_mask_z.unsqueeze(1 ).unsqueeze(-1 ).expand(-1 , attn_t.shape[1 ], -1 , attn_t.shape[-1 ]) attn_t = attn_t[box_mask_z] attn_t = attn_t.view(bs, hn, -1 , lens_s) attn_t = attn_t.mean(dim=2 ).mean(dim=1 ) else : attn_t = attn_t.mean(dim=2 ).mean(dim=1 ) sorted_attn, indices = torch.sort(attn_t, dim=1 , descending=True ) topk_attn, topk_idx = sorted_attn[:, :lens_keep], indices[:, :lens_keep] non_topk_attn, non_topk_idx = sorted_attn[:, lens_keep:], indices[:, lens_keep:] keep_index = global_index.gather(dim=1 , index=topk_idx) removed_index = global_index.gather(dim=1 , index=non_topk_idx) tokens_t = tokens[:, :lens_t] tokens_s = tokens[:, lens_t:] B, L, C = tokens_s.shape attentive_tokens = tokens_s.gather(dim=1 , index=topk_idx.unsqueeze(-1 ).expand(B, -1 , C)) tokens_new = torch.cat([tokens_t, attentive_tokens], dim=1 ) return tokens_new, keep_index, removed_index