前言
论文来源: RGB-T Tracking Based on Mixed Attention
大部分RGB-T跟踪算法都使用了CNN的下采样方法来提取目标特征, 然而大部分无意义的信息消耗了大量算力, 同时CNN难以理解目标与背景的关系. 而Transformer则解决了这些问题. 本文将使用特征级融合的方式, 集成两个模态的特征, 抑制低质量模态的影响, 从而提升RGB-T跟踪的准确率.
方法
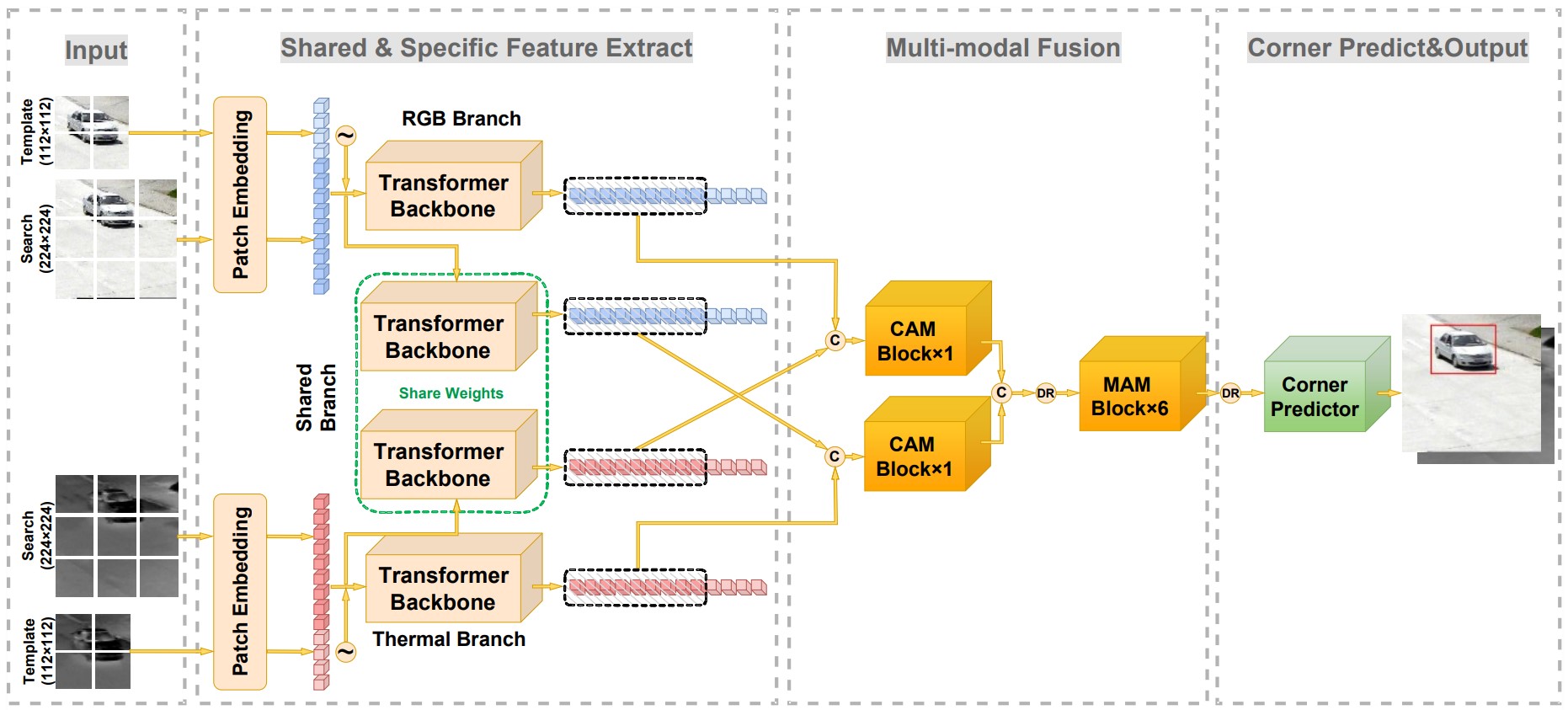
在上图中, 左侧是已被分割好的待搜索区域与目标模板, 其中 Patch Embedding 是将图像按照切割区域拼接为一维图像块. 在示意图中, 待搜索区域的大小是 224×224, 而一个 Patch 的大小是 16×16. 所以将会得到 196 个 Patch, 最终的维度为 [196,16×16×3=768]. 在这之后, 还需要添加位置信息, 待搜索区域直接使用ViT的预训练位置编码, 因为其大小恰好与待搜索区域大小一致; 目标模板处则使用两层全连接层构成的可学习位置编码, 但文中没有介绍具体结构. 最后, 我们得到了两个向量: z (目标模板,图中半透明的部分)与 x (待搜索区域,图中不透明的部分), 将其拼接到一起后, 输入Transformer主干网络:
r=Concat(z,x,dim=0)
第二个框中共有 4 个小模型, 其中上下两个分别是 RGB 特征提取分支和热红外特征提取分支, 中间两个是共享特征提取分支. 它们的输入是 r, 若设 Transformer 网络的第 n 层输出为 rn, 引入混合注意力的原理可以表示为以下公式:
r∗=rn−1+MA(rn−1)rn=r∗+FFN(r∗)
其中MA表示混合注意力(Mixed Attention), FFN表示前馈网络(Feedforward Neural Network).
令 a(x,y)=(xWQ)(yWK)/dk, 则 MA 的表达式如下:
softmax([a(zn,zn),a(xn,zn),a(xn,xn)a(xn,xn)])([znWVxnWV])
对于绿色框中的共享分支, 再次使用 ViT 作为主干网络, 此外还引入了 KL 散度损失, 用于确保输出特征在两种模式中的一致性.
现在, 已经拥有了RGB模态、热红外模态和共享模态的特征, 接下来需要将它们融合, 即网络结构图中的"Multi-modal Fusion"部分. 其详细结构如下图所示:
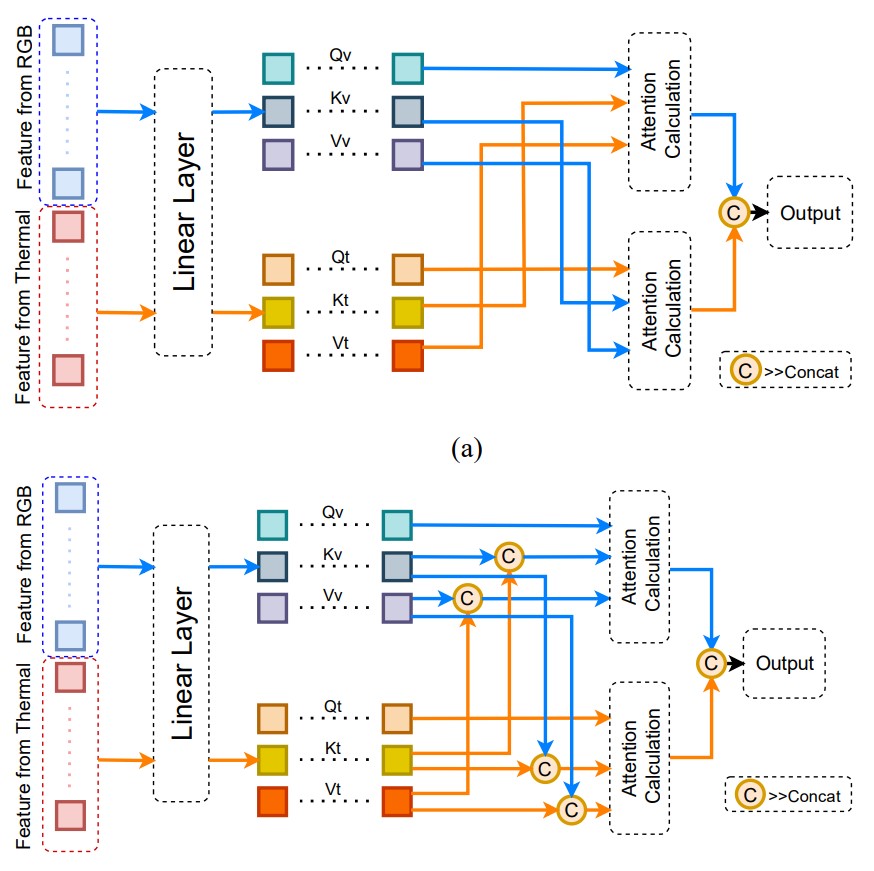
对于给定的可见光特征 xv, 热红外特征 xt, 首先将它们拼接到一起:
x=Concat(xv,xt)
使用线性层映射得到 Q,K,V 矩阵, 进行混合注意力(MA)计算,
softmax([a(xv,xv),a(xt,xv),a(xv,xt)a(xt,xt)])([xvvvxtvt])
计算交叉注意力(CA)时, 需要把两个模态连接起来
[softmax(a(xv,xt))∗xtvtsoftmax(a(xt,xv))∗xvvv]
定义
Hvt=Concat(Rvx,Gtx)Htv=Concat(Rtx,Gvx)
现在我们可以开始进行注意力计算. 注意此处开始才是模型的计算部分, 上面的 4 个公式是在说明计算方法.
Ctv=CAM(Htv)Cvt=CAM(Hvt)
此处再解释一下各个字母的含义, 下标 v 指可见光, t 指热红外, R 指两个分支的特征向量, G 指两个模态的输入, 上标 x 指待搜索区域.
作者使用了交叉注意力来融合特征, 是因为主干网络中已经对模态特征进行了增强, 不再需要更多的自注意力模块.
接下来将 CAM 的输出进行拼接, 降维(DR)后发送到 MAM 模块
Cmix=DR(Concat(Ctv,Cvt))Mmix=MAM(Ctv,Cvt)Output=DR(Mmix)
作者通过 RGBT234 数据集中的 carLight 序列(热红外主导)和 LasHeR 中的 leftmirror 序列(可见光主导)进行了验证, 最终发现该模型能够抑制低质量模态中的噪声, 让算法对主导模态的特征进行细化.
在这之后, 作者使用轻量级角点预测器来定位目标, 训练总共分为三阶段,
第一阶段模型的共享分支被冻结, 主要用于初始化模态特征分支的主干.
第二阶段, 共享分支被激活, 而模态特征主干的参数被保留并冻结. 同时 ViT 的前 8 个多头注意力模块也冻结, 仅激活后 4 个.
第三阶段, 冻结所有特征提取主干分支, 对模态融合网络进行训练.
第一和第三阶段的损失函数, 作者定义如下:
L=λgiouLgiou(bi,bi∗)+λL1L1(bi,bi∗)
其中 L1 表示 l1 损失, Lgiou 表示 GIoU 损失, λgiou 和 λL1 分别表示这两个损失的权重. bi 表示预测框, bi∗ 表示真实框.
第二阶段的损失如下:
L=min{λgiouLgiou(bv,bv∗)+λL1L1(bv,bv∗),λgiouLgiou(bt,bt∗)+λL1L1(bt,bt∗)+λKLLdiv(bv,bt)}
其中 Ldiv 表示 KL 散度损失, λKL 表示 KL 散度损失的权重, bv,bt 表示经过模态共享特征分支和角点预测器后从 RGB 以及 T 模态得到的目标边界框.
通过实验, 作者证明了 MACFT 在 RGBT234 与 LasHeR 数据集上均取得了较好的成功. 同时, 作者还对 RGBT234 的 12 个标记属性进行评估, 发现除了低光照以外, MACFT 均领先于其他模型.



