前言
论文来源: Region Selective Fusion Network for Robust RGB-T Tracking
可见光与热红外模态的融合, 为算法提供了更多的信息, 从而提高算法的准确率. 但是由于模态中场景的高度重叠, RGBT 数据中必然包含大量冗余信息. 同时每个模态的质量都会随时变化, 这意味着更多的误导信息. 本文将图像视为一个个不重叠的区域, 消除不可靠区域的误导信息, 保留高质量区域, 使算法专注于高质量特征.
方法
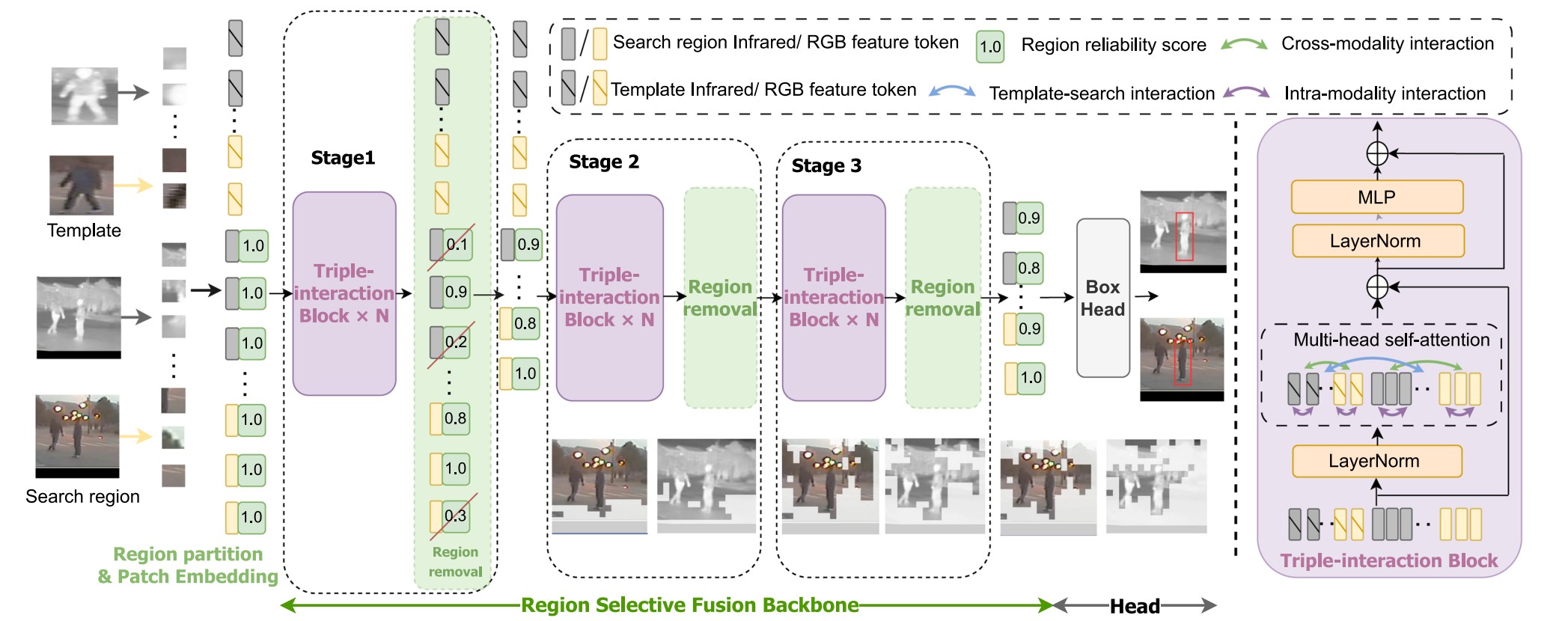
以 z 表示模板, x 表示搜索区域, 则它们能够表示为
Zm=[zm1E;zm2E;⋯,zmNzE]+PzXm=[xm1E;xm2E;⋯,xmNxE]+Px
其中 P 为位置嵌入, E 是投影矩阵, N 是 patch 数量. 同时候选区域的特征还需要加上令牌, 初始为 1.0.
图中的 Stage 表示区域选择性融合网络的三个阶段. 三个阶段均包含 N(N=3,4,3) 个三重交互模块和一个区域移除模块. 其中三重交互模块使用了多头注意力. 三重交互模块输出的结果会包含大量冗余, 而区域移除模块使用可靠性得分来移除不可靠的区域.
以第 i 个 RGB 模态的区域令牌 trgbi 为例:
r(trgbi)=Normi[α1j=1∑Nx(Wxrgb→xrgb[i,j])+α2j=1∑Nx(Wxrgb→xir[i,j])+α3j=1∑Nx(Wxrgb→z[i,j])]
其中 Normi 表示归一化, xrgb→xrgb 表示当前区域与其他区域的模态内相关性, 指示当前区域是目标还是背景; xrgb→xir 表示当前模态与另一模态的相关性, xrgb→z 表示与目标模板的相似度, α 为控制权重的超参数, 定义移除比 η=nk=0.3, k,n 分别表示需要删除的标记数量和区域总数量. 更大的 trgbi 表示该区域更重要, 而较小者将会被删除. 这就是区域移除模块的作用.
两个模态得到的结果不一定完全相同, 而在训练期间却没有考虑到这种不确定性, 作者采用了 Conv-BN-ReLU 层来预测角点的概率分布, 最终坐标采用各个角的概率分布的期望.
训练阶段, 定义损失函数为
Lreg=λL1L1(bi,b^i)+λgiouLgiou(bi,b^i)
其中 λ 为超参数权重, bi,b^i 分别是真实目标边界框和预测目标边界框.
通过实验, 作者发现该模型在多个数据集上的效果均优于文中提到的各种模型, 即使是在挑战性场景下, 模型仍能准确跟踪目标, 在拥有较高准确率的同时, FPS 达到了其他模型的 2 倍以上.
对于公式 2 中的超参数, 作者尝试了取 1 和 0, 即移除某些权重, 发现任何权重的消失都会对算法造成恶性影响, 只有同时取 1 时才达到最优效果.
在移除比 η 的取值上, 作者尝试了多个值, 更大的值会带来更高的性能, 但精度会先升高后降低, 最终作者选择了 0.3, 为最佳精度的取值.
以下是作者提供的结果可视化图片.
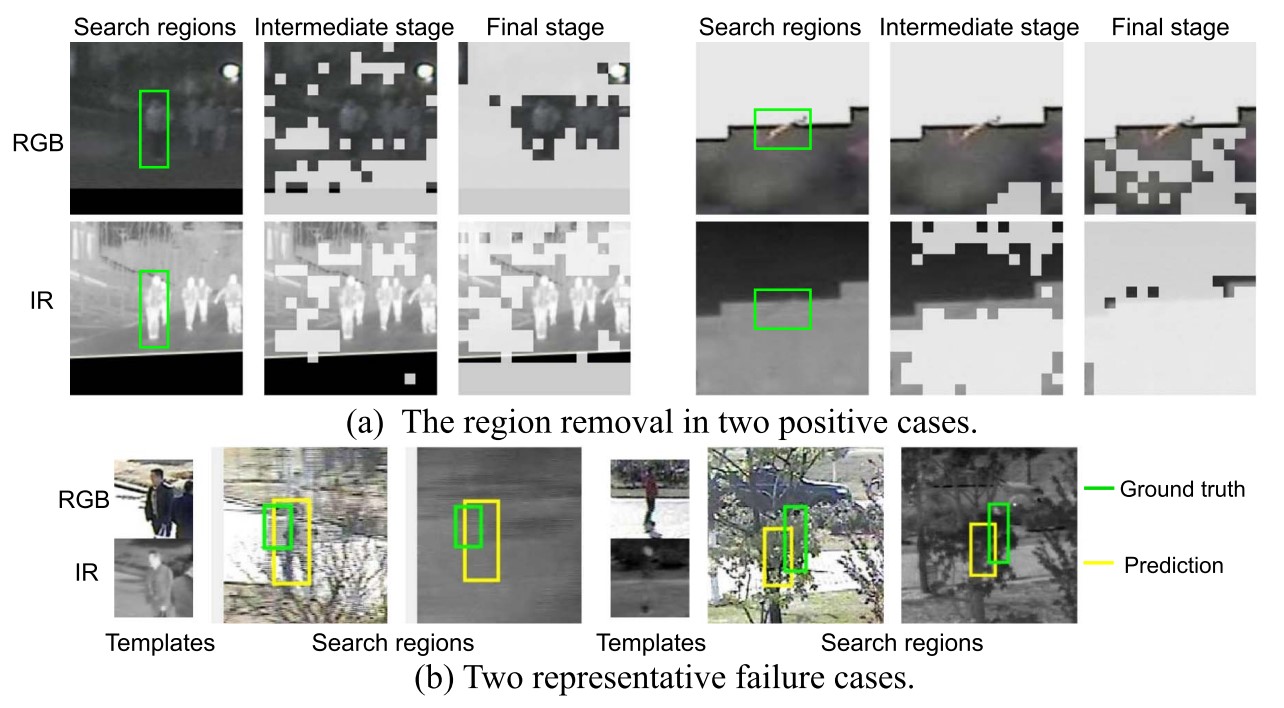
图 (a) 中显示了被移除的区域, 左图中 RGB 模态不可靠, 因而最终结果里大量 RGB 区域被移除, 而右图则恰恰相反.
图 (b) 展示了模型的不足之处, 当两个模态均不可靠时, 模型无法利用之前帧的结果.