



二叉搜索树的概念
二叉搜索树是一种特殊的二叉树,对于其中的任意结点 x,其左子树中的任何结点的值都小于结点 x 的值,其右子树中的任何结点的值都大于结点 x 的值
1 | struct Node{ |
因此只需要对二叉搜索树进行中序遍历,就可以升序输出所有元素
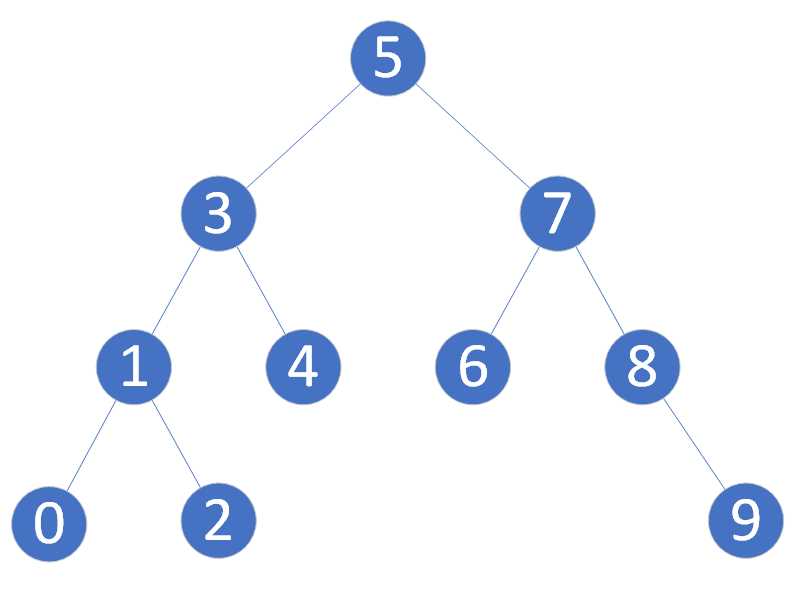
查询
为了查找二叉搜索树中是否存在value为key的项,我们可以采用递归的方法,如果当前结点不是要查找的项,则比较value和key的大小,以确定接下来需要访问左子树还是右子树
1 | Node* Search(Node* node, int key){ |
插入
二叉搜索树的插入操作与查询类似,都是不断地向下查找,直到找到一个子树为NULL的结点
例如上面的图片,如果往其中插入一个值: 20,那么这个值会被添加到 “9” 结点的右子树上
1 | bool Insert(Node *node, int key) { |
删除
删除操作较为复杂,删除一个结点时会出现3种情况
- 被删除的结点 x 没有子结点,那么只需要用NULL来替换父结点的子结点
- 被删除的结点 x 有一个子结点,那么只需要把父结点的子结点修改为 x 的子结点
- 被删除的结点 x 有两个子结点,此时情况较为复杂,我们需要从右子树中选取一个结点来替换 x 结点.考虑到二叉搜索树有一个特性: 右子树中的所有值一定比自己结点的值都要大.因此我们只需要选出右子树中最小值 y 来替换 x 结点,这样右子树中的剩余部分一定都比 y 更大.同理,也可以选出左子树中的最大值 n 来替换 x 结点.在删除最小值(最大值)结点时,可以递归调用自己,因为最值结点不可能存在两个子结点
时间复杂度
设二叉搜索树深度为 d
搜索与插入
插入操作在本质上与搜索是一样的,只不过搜索可能会在二叉树的中间停下,而插入会一直搜索到某个子结点不存在为止
只考虑最坏情况,就是把一颗二叉树从头访问到尾,二叉树的每个深度至多只被访问一次,因此时间复杂度为 O(d)
删除
删除操作的第一步是查找,设待删除项在二叉树的第 k 层,则查找操作的时间复杂度为 O(k),如果待删除结点有两个子结点,则需要从子树中查找最小值(最大值),此时子树的深度为 (d-k),则查找极值的最坏情况下时间复杂度为 O(d-k),因此最坏情况下删除操作的时间复杂度也是 O(d)
平均性能
二叉搜索树的高度会随着元素的插入和删除变化,并且与插入和删除的顺序密切相关.在平均情况下,二叉搜索树的时间复杂度的期望为 O(lgn),其性能远好于链表