并行与串行
在CPU上执行的代码是串行的,它的优点在于强逻辑性和强扩展性.代码必须严格按顺序执行,任何次序的错误都可能会导致程序出错.
在图形计算中,每个像素点的计算方法都是一致的,彼此之间没有关联,而GPU则拥有大量的核心,虽然每个核心都比不上CPU强,但是在处理大量简单计算时,速度会比CPU快很多.
AMP与CUDA
CUDA是英伟达提供的GPU编程编程模型,可以让开发者充分利用GPU的性能加速计算.但是使用CUDA需要自己下载文件,自己配置环境,对新手不友好.C++提供了amp.h头文件,可以便捷地开发并行计算应用,并且能够自动完成内存和显存的复制,降低了门槛,缺点是无法像CUDA那样进行高度自定义的计算和优化,因此效率不及CUDA.
AMP编程
从内存到显存
CPU中的所有类,函数,变量都是定义在内存中的,GPU无法读取内存,因此计算之前必须先把数据从内存复制到显存,同时复制所需的时间通常远大于计算所需的时间,因此需要尽可能减少复制的次数和数据量.例如,在USM锐化中,需要先计算高斯模糊图,再计算差值,可以将两步合并到一起,这样就能减少一次复制的次数.
在CUDA中,需要程序员手动复制数据,再手动释放,而AMP中已经为我们实现了复制功能,我们可以使用array_view来保存数据,而数据会在执行时自动复制到显存.
array_view类
头文件: amp.h
命名空间: Concurrency
array_view的使用方法与数组类似,可以直接用运算符“[]”来访问下标,以下代码定义了3个array_view类,并从3个已存在数组中取值
1 | const int length = 100; |
array_view的构造函数包括:类型,维数,长度,源数组,上述代码中定义了两个源数组为aCpp和bCpp的array_view类,且类型为const int,维数为1,长度为length.当定义多维数组时,需要指定所有的维数,例如
1 | array_view<const int, 2> a(n1, n2, aCpp); |
n1和n2即为两个维数.
你不需要严格按照源数组的维数来定义,也可以为一维数组定义二维array_view
1 | int aCpp[1000]; |
并发计算
parallel_for_each将会对范围内的所有元素并发执行指定函数
以下是利用parallel_for_each求和的代码
1 | parallel_for_each( |
restrict(amp)表示代码在GPU上执行,不能省略,否则会报错
index<1> idx表示一个一维索引向量,对于n维索引向量,需要改成index<n> idx
idx可以直接当作下标使用,也可以通过idx[i]来获取第i个分量,例如
1 | int a = idx[0]; |
以下两行代码的实际效果是相同的
1 | c[idx] = 100; |
网格结构
amp可以将array_view数组划分为网格结构,该视图称为平铺视图.
假设你需要计算马赛克,对一张1920*1080的图片,如果马赛克大小为10×10,则需要将维数为1920,1080的数组划分为10×10的网格,然后计算平均数,并填充到整个10×10区域.
amp中使用tile<n1,n2>来划分维数为n1,n2的二维网格,一个网格相对于全部网格的位置以向量形式储存在idx.global中,使用idx.global[i]来获取第i分量,一个元素相对于网格的位置以向量形式储存在idx.local中,使用idx.local[j]来获取第j分量.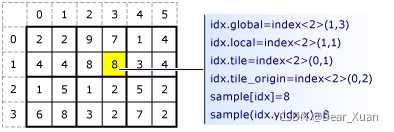
以下演示代码将4×4的二维数组划分为4个网格,每个网格的大小是2×2,并求这些网格中所有数的平均数
1 |
|
计算结果
线程同步
上面的代码中使用了两个array_view,但更多情况下我们需要直接修改源数据,这就会产生一个问题,源数据在另一个线程被修改了,导致自己线程读取了错误的数据.使用idx.barrier.wait()来要求当前线程暂停并等待其他线程,当所有线程都执行到这一步时再同时开始接下来的代码.
上面的代码中,a[idx.global]既被读取又被写入,如果某个线程在另一个线程读取之前写入了值,那么另一个线程就会读取错误的值.为了防止这种情况(实际上本代码在运行时几乎不会出现这种情况),需要线程在读取完成后立即暂停,并等待所有线程读取后再开始接下来的代码,因此上面代码的parrallel_for_each内的函数可以修改为
1 | tile_static int grid[2][2]; |
受限函数
在GPU中运行的函数称为受限函数,受限函数的标识符是restrict(amp),下列演示代码将传入的num值加一并返回
1 | int add(int num) restrict(amp) { |
amp表示函数运行在GPU上,因此该函数只能在GPU中执行,如果在其他地方使用了该函数便会报错,将amp改成cpu则表示函数在CPU上执行,省略不写也表示在CPU上运行.如果希望函数能够同时在CPU和GPU上运行,则需要改用标识符restrict(amp,cpu),但是你必须保障函数内的代码同时符合amp和cpu的规则.
restrict(amp) 也可以写成 __GPU_ONLY
同理
restrict(cpu) 也可以写成 __CPU_ONLY
restrict(amp,cpu) 则可以写成 __CPU_ONLY __GPU_ONLY
1 | void add() __CPU_ONLY __GPU_ONLY{ |
这看起来有点变扭,但确实是可行的.
在受限函数中无法使用以下项
递归
指向非函数或结构体的指针
goto,try,catch,throw语句
全局变量和静态变量
这意味着你不能在受限函数中调用其他非受限函数,即printf,rand(),sqrt等适用于CPU的函数都无法在GPU中执行,但是你可以使用函数名的方式来调用其他受限函数.
内核函数中的静态变量
用tile_static修饰的变量只能在内核中被定义,并在内核函数结束(所有能够读取该变量的线程结束)时被销毁.在上面的求平均数演示代码中,定义了如下静态变量
1 | tile_static int grid[2][2]; |
grid是一个包含4个数的二维数组,grid总共被4个线程访问,这4个线程都拥有相同的idx.global属性和不同的idx.local属性,每个线程根据自己的idx.local来修改总共4个值中的一个值,这里的grid就是一个全局变量.相同的网格(即相同的idx.global)拥有相同且唯一的grid,而不同网格的grid是不同的.
tile_static最好在平铺视图中定义,如果你没有使用平铺视图,则会发出警告.tile_static定义的变量不能初始化,不能修饰指针.IDE可能不会立即报错,但是执行时会遇到错误.
数学计算与图形计算
前面已经说过AMP中无法使用sqrt等数学函数,但是AMP已经为我们提供了数学库与图形库,可以方便地拿来使用.它们的头文件分别是
1 |