本文将通过C#调用dll的方法来实现并发计算
Dll定义
在VS2019里新建动态链接库项目,在pch.h里定义函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#ifndef PCH_H
#define PCH_H
#include "framework.h"
extern "C" _declspec(dllexport) void Sum(int* s,int a[],int b[],int length);
#endif
|
在pch.cpp里实现该函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#include "pch.h"
#include <amp.h>
using namespace Concurrency;
extern "C" _declspec(dllexport) void Sum(int* s, int a[], int b[],int length) {
array_view<const int, 1> aArray(length, a);
array_view<const int, 1> bArray(length, b);
array_view<int, 1> sum(length, s);
parallel_for_each(
sum.extent,
[=](index<1> idx) restrict(amp) {
sum[idx] = aArray[idx] + bArray[idx];
}
);
}
|
该函数接收4个参数,分别用来储存结果,a数组,b数组,数组长度,并将a和b数组相加,结果储存在s里面.
array_view表示包含在一个容器中的数据的N维视图,各项参数的含义如下
const int:类型,
1:维数
aArray:array_view的实例
length:长度
a:数据源
如果是二维数组,则要改成下面的形式
1
| array_view<const int, 2> aArray(width,height, a);
|
parallel_for_each语句能够进行并发计算,index<1>指idx是一维的,如果是二维数组,需要改成index<2>,此时idx相当于(i,j),通过idx[0]和idx[1]获得行号和列号
例如
1
2
| int row = idx[0];
int col = idx[1];
|
aArray[idx]和aArray(row,col)是等效的
Dll导入
将上述代码生成dll,并放在C#程序的目录下
导入刚刚写的dll
1
2
| [DllImport("Dll1.dll", EntryPoint = "Sum", CallingConvention = CallingConvention.Cdecl)]
public static extern void Sum(IntPtr s,int[] a, int[] b,int length);
|
随机数求和
生成随机数数组,求和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| static void Main(string[] args)
{
const int size = 100;
int[] s = new int[size];
int[] a = new int[size];
int[] b = new int[size];
Random random = new Random();
for(int i = 0; i < size; i++)
{
a[i] = random.Next(0, 100);
b[i] = random.Next(100, 200);
}
unsafe
{
IntPtr p = Marshal.UnsafeAddrOfPinnedArrayElement(s, 0);
Sum(p, a, b, size);
}
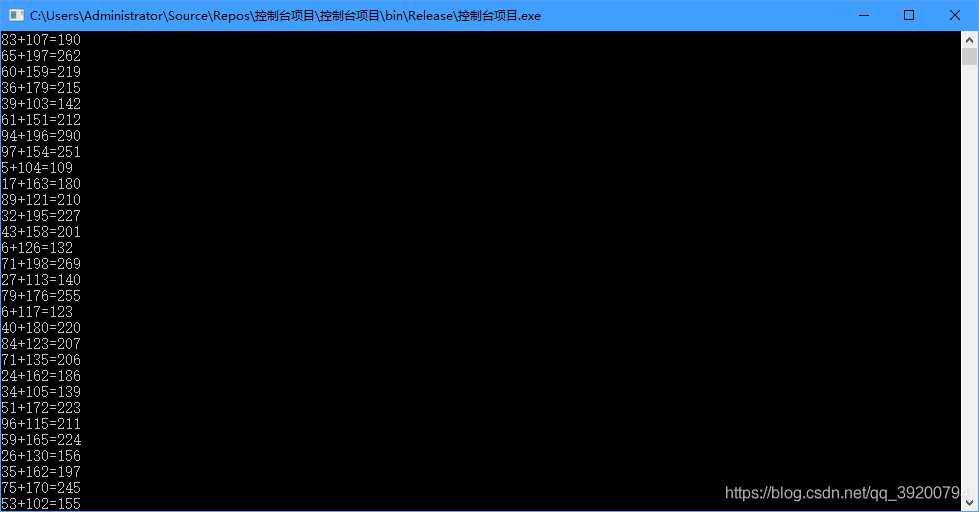
for(int i = 0; i < size; i++)
{
Console.WriteLine(a[i] + "+" + b[i] + "=" + s[i]);
}
Console.ReadLine();
}
|
使用StopWatch类来计算耗时(命名空间System.Diagnostics)
1
2
3
4
5
6
7
8
| Stopwatch watch1 = new Stopwatch();
watch1.Start();
for(int i = 0; i < size; i++)
{
s[i] = a[i] + b[i];
}
watch1.Stop();
Console.WriteLine("CPU耗时:" + watch1.Elapsed.TotalMilliseconds);
|
1
2
3
4
5
| Stopwatch watch2 = new Stopwatch();
watch2.Start();
Sum(p, a, b, size);
watch2.Stop();
Console.WriteLine("GPU耗时:" + watch2.Elapsed.TotalMilliseconds);
|
由于加载dll本身需要时间,所以在计时之前需要先调用一次Sum函数.
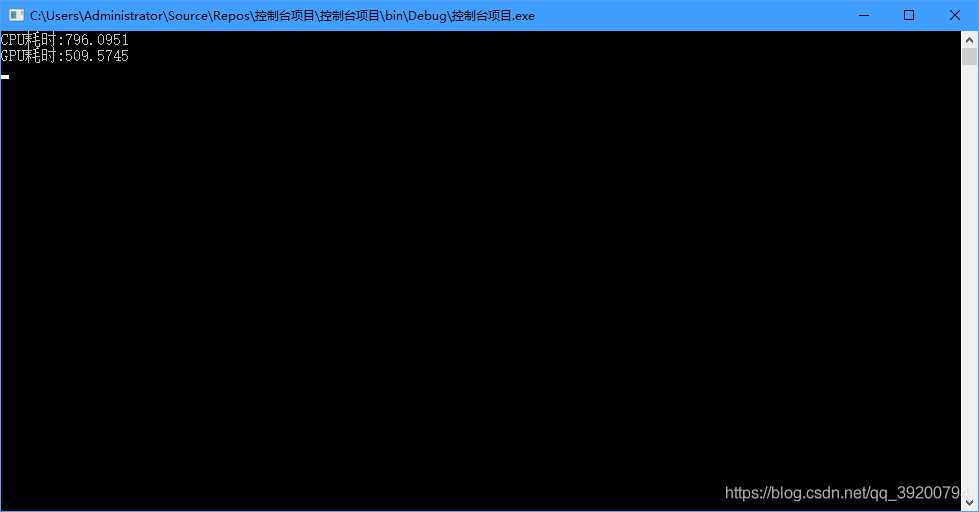
测试代码是计算4亿个数的和,可以看到GPU计算比CPU计算少了300毫秒,但是CPU在循环2亿次的情况下居然仅仅比GPU多了300毫秒,这是因为GPU无法从内存读取数据,需要把数据先复制到显存里才能计算,计算完又需要把数据复制回来,而主要时间开销都在数据的复制里面.
现实情况下,循环体里不可能只有一行代码,假设循环体里有10个语句,那么CPU的执行时间就会翻10倍,而GPU的执行时间也会翻10倍,但是由于主要耗时操作是数据的复制,所以实际增长不会特别明显.
下面我们修改一下代码.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| extern "C" _declspec(dllexport) void Sum(int* s, int a[], int b[],int length) {
array_view<const int, 1> aArray(length, a);
array_view<const int, 1> bArray(length, b);
array_view<int, 1> sum(length, s);
parallel_for_each(
sum.extent,
[=](index<1> idx) restrict(amp) {
sum[idx] = aArray[idx] + bArray[idx];
if (idx[0] % 5 == 0) {
sum[idx] += 5;
}
if (idx[0] % 7 == 0) {
sum[idx] += 7;
}
if (idx[0] % 11 == 0) {
sum[idx] += 11;
}
if (idx[0] % 13 == 0) {
sum[idx] += 13;
}
if (idx[0] % 17 == 0) {
sum[idx] += 17;
}
}
);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| watch1.Start();
for(int i = 0; i < size; i++)
{
s[i] = a[i] + b[i];
if (i % 5 == 0)
{
s[i] += 5;
}
if (i % 7 == 0)
{
s[i] += 7;
}
if (i % 11 == 0)
{
s[i] += 11;
}
if (i % 13 == 0)
{
s[i] += 13;
}
if (i % 17 == 0)
{
s[i] += 17;
}
}
watch1.Stop();
Console.WriteLine("CPU耗时:" + watch1.Elapsed.TotalMilliseconds);
|
这次改用100万量级的数据
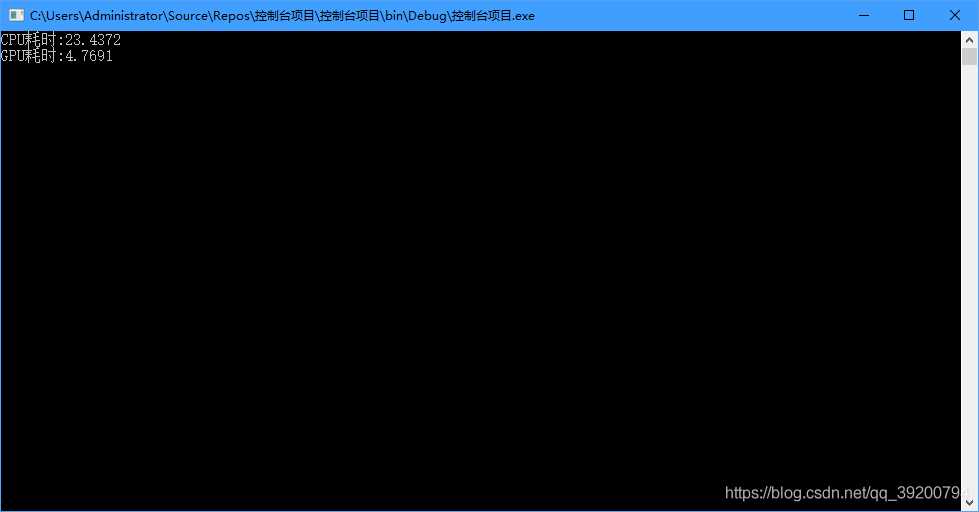
现在GPU的优势就完全体现出来了



