敏感词过滤说白了就是简单的字符串替换,Java本身已经提供了相关函数,但是一旦遇到长文本,或者敏感词数量庞大,效率下降就会非常明显.本文将介绍利用多叉树进行敏感词存储和过滤的方法.
多叉树
多叉树是一种特殊的数据结构,如下图
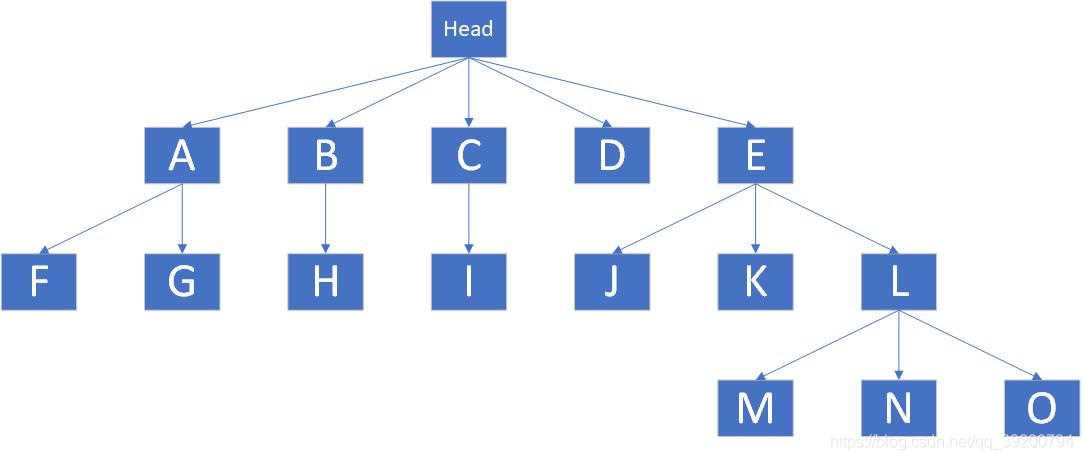
Head为头节点,下面的ABCDE均为子树.那么多叉树是如何存储敏感词的呢?首先将敏感词分解为一个一个的字符,例如敏感词"CSDN",第一个字符是C,则在Head下创建子树"C"(如果已经存在则跳过这一步).第二个字符是S,则在子树"C"下面创建"S"接下来是D,N,创建完N就可以结束了.如此循环,就可以创建出类似上图的多叉树.
检测敏感词时,对于字符串中的每一个字符,先查找Head下是否有存在对应子树,例如字符串"ELN",先读取第一个字符E,并检查Head,发现存在子树"E";于是读取第二个字符L,并检查子树E的子树,发现存在L;最后读取第三个字符N,发现子树N还是存在.此时发现子树N后面没有内容,这说明ELN是一个敏感词,于是将ELN替换成"***".
这种算法会出现一个小意外,如果一个敏感词恰好是另一个敏感词的前缀,就会导致较短的敏感词被长的敏感词覆盖,这种情况可以通过添加结束标记来区分.不过我的想法是,如果出现这种情况,直接把前缀屏蔽掉就行了,这样后半段也不算敏感词了(好像实际工作中不能这样做),因此我没有添加结束标记.
代码
首先要先写一个数据结构来模拟多叉树,下图里Word就是一颗树,里面保存着当前字符c和子树next,compareTo是用来排序的,以提高查找效率.
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class Word implements Comparable<Word>{
public char c;
public List next = null;
public Word(char c){
this.c = c;
}
@Override
public int compareTo(Word word) {
return c - word.c;
}
}
|
上图的List继承了ArrayList,主要是因为ArrayList可以动态添加元素,便于偷懒
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import java.util.ArrayList;
public class List extends ArrayList<Word> {
public Word get(char c){
for(Word w :this){
if(w.c == c) return w;
}
return null;
}
public Word binaryGet(char c){
int left,right,key;
Word word;
left = 0;right = this.size()-1;
while (left <= right){
key = (left + right) / 2;
word = get(key);
if(word.c == c){
return word;
}else if(word.c > c){
right = key - 1;
}else {
left = key + 1;
}
}
return null;
}
public Word add(char c){
Word word = new Word(c);
super.add(word);
return word;
}
}
|
以下是核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
| import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
public final class SensitiveWordFilter {
public static List wordList;
private final static char replace = '*';
private final static char[] skip = new char[]{
'!','*','-','+','_','=',',','.','@'
};
public static String Filter(String text){
if(wordList == null || wordList.size() == 0) return text;
char[] __char__ = text.toCharArray();
int i,j;
Word word;
boolean flag;
for(i=0;i<__char__.length;i++){
char c = __char__[i];
word = wordList.binaryGet(c);
if(word != null){
flag = false;
j = i+1;
while (j < __char__.length){
if(skip(__char__[j])) {
j++;
continue;
}
if(word.next != null){
word = word.next.get(__char__[j]);
if(word == null){
break;
}
j++;
}else {
flag = true;
break;
}
}
if(word != null && word.next == null){
flag = true;
}
if(flag){
while (i<j){
if(skip(__char__[i])){
i++;
continue;
}
__char__[i] = replace;
i++;
}
i--;
}
}
}
return new String(__char__);
}
public static void loadWord(ArrayList<String> words){
if(words == null) return;
char[] chars;
List now;
Word word;
wordList = new List();
for(String __word__:words){
if(__word__ == null) continue;
chars = __word__.toCharArray();
now = wordList;
word = null;
for(char c:chars){
if(word != null) {
if(word.next == null) word.next = new List();
now = word.next;
}
word = now.get(c);
if(word == null) word = now.add(c);
}
}
sort(wordList);
}
public static void loadWordFromFile(String path){
String encoding = "UTF-8";
File file = new File(path);
try{
if(file.isFile() && file.exists()){
InputStreamReader inputStreamReader = new InputStreamReader(
new FileInputStream(file),encoding
);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line;
ArrayList<String> list = new ArrayList<>();
while ((line = bufferedReader.readLine()) != null){
list.add(line);
}
bufferedReader.close();
inputStreamReader.close();
loadWord(list);
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static void sort(List list){
if(list == null) return;
Collections.sort(list);
for(Word word:list){
sort(word.next);
}
}
private static boolean skip(char c){
for(char c1:skip){
if(c1 == c) return true;
}
return false;
}
}
|
测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class Main {
public static void main(String[] args) throws Exception{
SensitiveWordFilter.loadWordFromFile("D:/SensitiveWordList.txt");
StringBuilder stringBuilder = new StringBuilder();
long t1,t2;
for(int i=0;i<100;i++){
stringBuilder.append("123TM,D123");
}
String s = stringBuilder.toString();
String result = null;
t1 = System.nanoTime();
for(int i=0;i<10000;i++){
result = SensitiveWordFilter.Filter(s);
}
t2 = System.nanoTime();
System.out.println(result);
System.out.println((t2 - t1) / 1000000 + "毫秒");
}
}
|
测试使用的敏感词库总共包含14596个敏感词(可能有个别重复),在测试代码里生成了一个长度为1000的字符串,总共包含100个相同敏感词,敏感词中间有逗号隔开
重复执行过滤10000次,并打印结果和时间,结果如下

可以看到程序成功地过滤了敏感词,并保留了逗号,总耗时335毫秒,平均每次过滤仅需要0.03毫秒,并且是在上万个敏感词和超长字符串的情况下.
源文件+敏感词列表
在寻找敏感词列表时发现很多人的分享都被取消了,为了防止敏感词列表被检测出敏感词,使用了zip格式并加密.敏感词库存在部分重复,不过不影响使用.
密码:dearxuan
密码:dearxuan
密码:dearxuan



